O que acontece no cérebro quando um comportamento é reforçado?
Um artigo didático e aprofundado para estudantes de Psicologia e leitores interessados em neurociência comportamental
NEUROCIÊNCIAPSICOLOGIA
Compartilhe esta publicação:
Introdução — uma cena cotidiana
Você já percebeu como é fácil checar o celular após ouvir o tique de uma notificação? Ou como uma pequena recompensa — um “like”, um elogio, um quadradinho de chocolate — pode aumentar muito a probabilidade de repetir um comportamento?
Esses exemplos simples são janelas poderosas para entender o reforçamento: uma relação entre evento (recompensa) e comportamento que, quando bem estabelecida, muda a frequência com que agimos.
Neste artigo, atravessaremos três camadas:
O conceito comportamental de reforço.
Os mecanismos neurais que permitem que reforços “mudem” o cérebro.
Aplicações práticas e implicações éticas.
Meu objetivo é integrar Análise Experimental do Comportamento (AEC) e neurociência cognitiva de forma sólida, atual e acessível.
1. O que é reforço, afinal?
Na AEC, reforço é qualquer consequência que aumenta a probabilidade futura de um comportamento ocorrer sob as mesmas condições.
Reforçamento positivo: apresentação de um estímulo agradável (ex.: elogio após uma tarefa bem feita).
Reforçamento negativo: remoção de um estímulo aversivo (ex.: retirar o sapato quando ele está machucando o pé).
O ponto crucial é que reforço não é “recompensa” no sentido moral. É uma relação funcional entre comportamento e consequência — e essa relação altera a probabilidade futura de ação.
2. Tempo é tudo: reforço imediato vs. atrasado
Reforços imediatos tendem a ser mais eficazes do que atrasados. Psicologicamente, a proximidade temporal entre resposta e consequência facilita a associação.
Neurobiologicamente, isso se explica pela janela temporal da plasticidade sináptica: quando um comportamento é seguido rapidamente por um estímulo reforçador, o cérebro registra essa sequência como causal, fortalecendo as conexões neurais envolvidas [1].
Em outras palavras: quanto mais rápido o reforço, mais forte a aprendizagem.
3. A dopamina e o erro de previsão de recompensa
A dopamina é a grande protagonista dessa história — mas nem sempre da forma como muitos imaginam.
Durante décadas, acreditou-se que a dopamina era simplesmente a “molécula do prazer”. Hoje sabemos que ela está mais ligada à motivação, expectativa e aprendizado do que à sensação de prazer em si [2][3].
Neurônios dopaminérgicos, localizados principalmente na área tegmental ventral (VTA) e na substância negra, projetam-se para o núcleo accumbens, estriado e córtex pré-frontal — regiões que formam o sistema de recompensa [4].
Esses neurônios não apenas disparam quando recebemos algo prazeroso, mas também quando antecipamos algo prazeroso. Isso se chama erro de previsão de recompensa (reward prediction error, ou RPE):
Se a recompensa é melhor do que o esperado, há aumento da atividade dopaminérgica.
Se é igual ao esperado, a atividade se mantém.
Se é pior do que o esperado, a atividade cai [5].
Esse mecanismo permite ao cérebro ajustar suas expectativas e aprender o que realmente vale a pena repetir.
4. As principais estruturas envolvidas
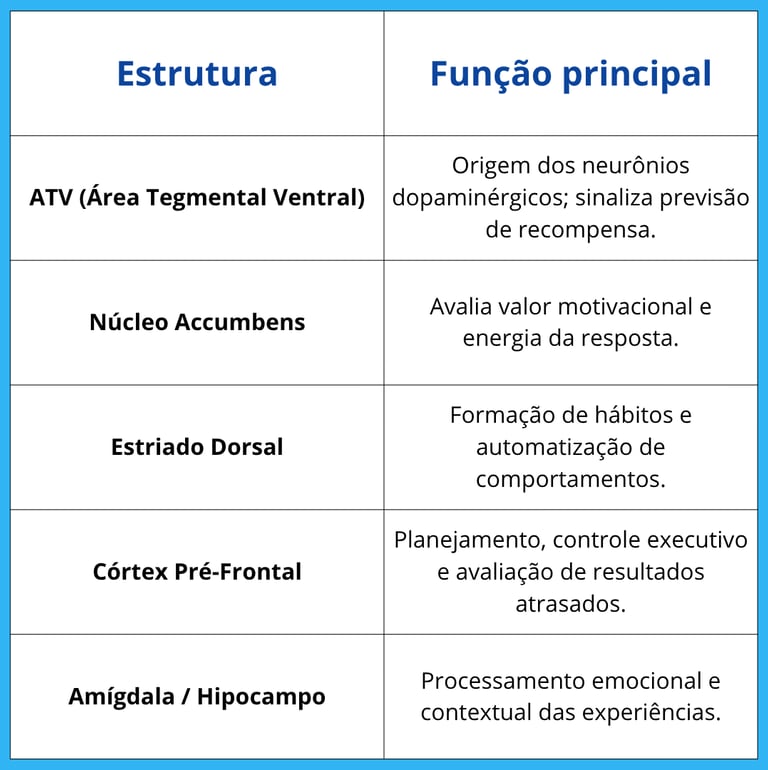
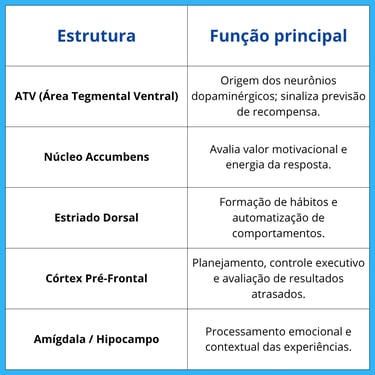
Essas regiões trabalham em rede, transformando reforços ambientais em mudanças comportamentais duradouras.
5. Reforço e plasticidade sináptica
Quando um comportamento é reforçado, as sinapses envolvidas se fortalecem por meio da potenciação de longo prazo (LTP) — um processo que aumenta a eficiência na transmissão entre neurônios [6][7].
Esse fenômeno depende de receptores glutamatérgicos (NMDA, AMPA) e fatores neurotróficos (como BDNF), que promovem mudanças estruturais reais no cérebro.
Em resumo: reforçar é moldar o cérebro — literalmente.
6. Da escolha ao hábito: a transição neural
Com a repetição, o controle de um comportamento muda de lugar no cérebro.
No início, a ação é guiada por metas (sistema ventral, sensível ao valor). Com o tempo, o controle migra para o estriado dorsal, tornando-se automático [8].
Esse processo explica por que hábitos — bons ou ruins — são tão resistentes: eles deixam de depender da reflexão consciente e passam a ser acionados por gatilhos contextuais.
Modificar um hábito requer reativar o sistema de metas e criar novas contingências de reforço.
7. Programações de reforço: por que algumas recompensas viciam mais
B. F. Skinner demonstrou que o padrão de reforço — isto é, a forma como e com que frequência as recompensas são distribuídas — influencia profundamente não apenas a rapidez com que aprendemos um comportamento, mas também o quanto ele se torna resistente à extinção e o grau de motivação que sentimos ao executá-lo.
Em outras palavras, não é apenas o que nos recompensa que importa, mas como essa recompensa é entregue. A regularidade (ou imprevisibilidade) do reforço altera diretamente o modo como o cérebro libera dopamina e consolida as sinapses envolvidas na ação.
7.1 Reforço contínuo: o aprendizado rápido, porém frágil
No reforço contínuo, cada comportamento é seguido de uma recompensa imediata e previsível. Esse padrão é extremamente eficaz nas fases iniciais do aprendizado, pois ajuda o cérebro a estabelecer rapidamente a conexão entre ação e consequência.
Por exemplo: um estudante que se permite assistir a um episódio da série favorita sempre que completa um bloco de estudos, ou um aplicativo de idiomas que exibe medalhas toda vez que o usuário conclui uma lição.
Nessas situações, o sistema dopaminérgico aprende que “ação gera recompensa” com alta previsibilidade. O núcleo accumbens libera dopamina logo após o comportamento, fortalecendo as sinapses correspondentes e facilitando o aprendizado [13].
No entanto, esse tipo de reforço também leva a uma rápida extinção quando as recompensas deixam de ocorrer. Assim que o cérebro percebe que o comportamento não gera mais o retorno esperado, os níveis de dopamina caem e a motivação desaba. É por isso que o reforço contínuo é ideal para instalar novos hábitos, mas ineficaz para mantê-los a longo prazo.
7.2 Reforço intermitente: o poder da imprevisibilidade
No reforço intermitente, o comportamento nem sempre é seguido de recompensa. Em vez disso, ela aparece ocasionalmente, de maneira irregular ou imprevisível.
Do ponto de vista neurocientífico, esse padrão ativa de forma intensa o mecanismo de erro de previsão de recompensa (reward prediction error, RPE). Quando a recompensa é incerta, a área tegmental ventral (VTA) e o núcleo accumbens liberam pulsos dopaminérgicos mais fortes a cada reforço inesperado, e até mesmo antes da recompensa ocorrer, durante a expectativa [14].
Esse tipo de reforço mantém o cérebro em um estado constante de busca e vigilância — o que torna o comportamento muito mais resistente à extinção. Mesmo quando as recompensas param de vir por um tempo, o sistema dopaminérgico continua ativo, esperando o próximo estímulo.
É o mesmo princípio explorado por redes sociais, jogos online e aplicativos, que alternam entre momentos neutros e recompensas aleatórias (curtidas, comentários, notificações, prêmios virtuais). A incerteza é o motor do engajamento.
7.3 Subtipos de reforço intermitente
O reforço intermitente pode ser dividido em quatro principais programações, cada uma com efeitos distintos sobre o comportamento.
8. Reforço social e simbólico
O cérebro responde de modo semelhante a elogios, dinheiro ou aprovação social quanto a recompensas físicas [10].
Reforços condicionados (como “likes” ou reconhecimento) ativam o mesmo circuito dopaminérgico que o prazer gustativo ou tátil. Isso explica por que o reforço social é tão poderoso — e também por que redes sociais conseguem gerar comportamentos repetitivos e compulsivos.
9. Aplicações práticas — do laboratório à vida real
O princípio é simples, mas poderoso:
“O comportamento é função de suas consequências.” — B. F. Skinner
Para aplicar o reforçamento de forma ética e eficaz:
Defina o comportamento alvo (observável e mensurável).
Escolha reforçadores relevantes e imediatos.
Estabeleça contingência clara (quando X ocorre, Y é entregue).
Comece com reforço contínuo, depois reduza a frequência.
Monitore dados e ajuste quando necessário.
Generalize para contextos naturais.
Usar esses princípios em terapia, educação ou desenvolvimento pessoal é uma forma de aliar psicologia científica e neurociência aplicada.
10. Conclusão — a ponte entre comportamento e cérebro
Quando um comportamento é reforçado, uma sequência complexa entra em ação:
O ambiente fornece uma consequência contingente.
O cérebro libera dopamina sinalizando a diferença entre expectativa e resultado.
Sinapses específicas se fortalecem (ou enfraquecem) com base nesse feedback.
Com a repetição, o comportamento se automatiza, tornando-se hábito.
Mas é importante compreender que o reforço é um fenômeno multifacetado.
Nem todos os neurônios dopaminérgicos funcionam da mesma forma; alguns respondem à novidade, outros ao movimento ou à incerteza [11]. Além disso, sistemas como o opioide endógeno e o endocanabinoide também participam do prazer, da saciedade e da motivação [12].
Ou seja, o cérebro é mais complexo do que qualquer modelo isolado — mas a essência permanece:
Reforço é aprendizagem moldada pela experiência.
E essa aprendizagem acontece tanto no comportamento observável quanto nas conexões microscópicas que sustentam o pensamento e a ação.
Referências
Citri, A., & Malenka, R. C. (2008). Synaptic plasticity: Multiple forms, functions, and mechanisms. Neuropsychopharmacology, 33(1), 18–41.
🔗 https://doi.org/10.1038/sj.npp.1301559The debate over dopamine's role in reward: the case for incentive salience
🔗 https://doi.org/10.1007/s00213-016-4032-6Berridge, K. C., & Robinson, T. E. (2016). Liking, wanting, and the incentive-sensitization theory of addiction. American Psychologist, 71(8), 670–679.
Wise, R. A. (2004). Dopamine, learning and motivation. Nature Reviews Neuroscience, 5(6), 483–494.
🔗 https://doi.org/10.1038/nrn1406Schultz, W. (1998). Predictive reward signal of dopamine neurons. Journal of Neurophysiology, 80(1), 1–27.
🔗 https://doi.org/10.1152/jn.1998.80.1.1Lüscher, C., & Malenka, R. C. (2012). NMDA receptor-dependent long-term potentiation and depression (LTP/LTD). Nature Neuroscience, 15, 1145–1150.
🔗 https://doi.org/10.1038/nn.3171Synaptic plasticity of NMDA receptors: mechanisms and functional implications
🔗 https://www.sciencedirect.com/science/article/abs/pii/S0959438812000098
Everitt, B. J., & Robbins, T. W. (2016). Drug addiction: updating actions to habits to compulsions ten years on. Annual Review of Psychology, 67, 23–50.
Ferster, C. B., & Skinner, B. F. (1957). Schedules of reinforcement. Appleton-Century-Crofts.
📘 [Livro clássico — sem link, disponível em bibliotecas acadêmicas e reedições digitais.]Izuma, K., Saito, D. N., & Sadato, N. (2008). Processing of social and monetary rewards in the human striatum. Neuron, 58(2), 284–294.
🔗 https://doi.org/10.1016/j.neuron.2008.03.020da Silva, J. A., Tecuapetla, F., Paixão, V., & Costa, R. M. (2018). Dopamine neuron activity before action initiation gates and invigorates future movements. Nature, 554(7691), 244–248.
🔗 https://doi.org/10.1038/nature25457Leknes, S., & Tracey, I. (2008). A common neurobiology for pain and pleasure. Nature Reviews Neuroscience, 9(4), 314–320.
🔗 https://doi.org/10.1038/nrn2333Schultz, W. (2016). Dopamine reward prediction error coding.
Montague, P. R., Dayan, P., & Sejnowski, T. J. (1996). A framework for mesencephalic dopamine systems based on predictive Hebbian learning. Journal of Neuroscience, 16(5), 1936–1947.
Fiorillo, C. D., Tobler, P. N., & Schultz, W. (2003). Discrete coding of reward probability and uncertainty by dopamine neurons. Science, 299(5614), 1898–1902.
O’Doherty, J. P. (2004). Reward representations and reward-related learning in the human brain: insights from neuroimaging. Current Opinion in Neurobiology, 14(6), 769–776.
🔗 https://www.sciencedirect.com/science/article/abs/pii/S0959438804001680
Lieberman, M. D. (2013). Social: Why Our Brains Are Wired to Connect. New York: Crown Publishers.
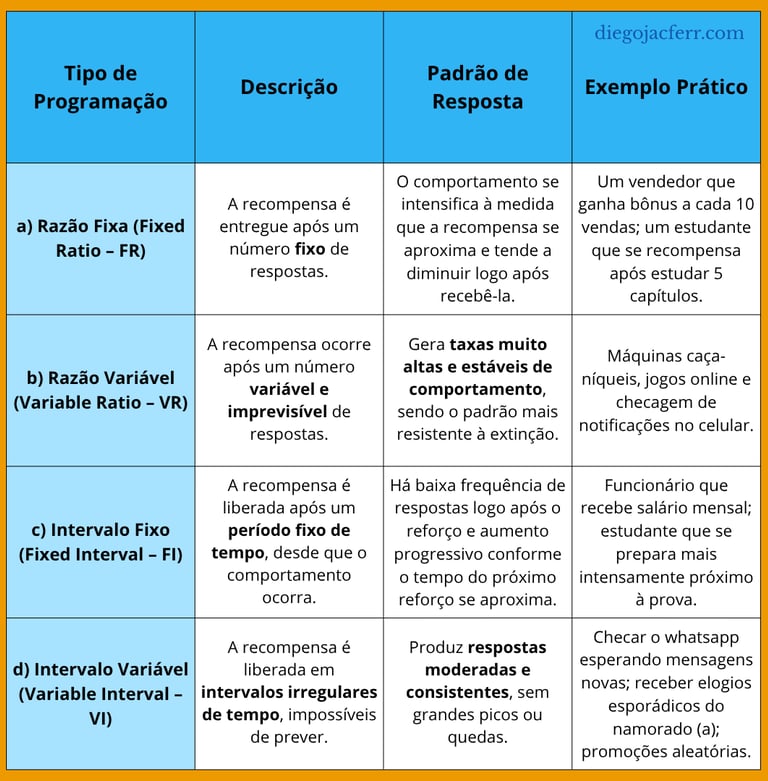
7.4 O que acontece no cérebro em cada tipo de reforço
A neurociência mostra que esses padrões ativam o sistema de recompensa de maneiras diferentes.
Reforço contínuo: o cérebro rapidamente aprende a prever a recompensa. A dopamina é liberada durante o comportamento, mas tende a diminuir quando a recompensa se torna garantida. O aprendizado é rápido, mas o interesse desaparece quando o reforço some.
Reforço intermitente de razão variável: cada reforço inesperado gera um pico dopaminérgico maior do que o anterior, pois o cérebro não sabe quando o próximo virá. Essa oscilação imprevisível mantém o comportamento ativo por longos períodos — é o padrão que mais se aproxima do mecanismo de vício comportamental [15].
Reforço de intervalo variável: ativa o sistema dopaminérgico de forma mais suave e prolongada, mantendo o engajamento sem dependência extrema. É uma programação muito usada em ambientes de aprendizado, pois promove persistência sem exaustão.
Pesquisas com neuroimagem funcional mostram que recompensas imprevisíveis ativam não apenas o núcleo accumbens, mas também o córtex orbitofrontal e o cíngulo anterior, áreas associadas à avaliação de risco e expectativa [16]. Isso explica por que situações incertas tendem a nos manter mais alertas e motivados.
7.5 Aplicações práticas: foco, hábito e produtividade
Compreender as programações de reforço permite usar conscientemente o mesmo mecanismo que as redes sociais e jogos exploram para nos capturar, mas de forma construtiva — direcionando-o para o desenvolvimento de hábitos positivos e aumento da produtividade.
Na formação de hábitos:
Use reforço contínuo no início (ex.: recompense-se toda vez que cumpre a meta de estudo ou treino).
À medida que o hábito se solidifica, mude para reforço intermitente: recompensas ocasionais, de forma imprevisível, mantendo o cérebro interessado sem criar dependência da recompensa.
Na gestão do foco:
Alternar entre períodos de trabalho e pausas com pequenas recompensas (como café, alongamento, música ou tempo livre) cria previsibilidade. Mas introduzir elementos de surpresa — por exemplo, mudar a ordem das tarefas, variar o tipo de recompensa — mantém o sistema dopaminérgico ativo e evita o tédio.Na aprendizagem:
Professores e mentores podem alternar reforços previsíveis (feedback imediato, elogios) com reforços variáveis (atividades surpresa, desafios inesperados). Essa variação ativa o córtex pré-frontal e melhora a consolidação de memória [17].Na autorregulação digital:
Reconhecer que redes sociais usam reforço de razão variável (curtidas e notificações imprevisíveis) ajuda a desenvolver consciência metacognitiva: entender o mecanismo é o primeiro passo para resistir a ele.
7.6 O cérebro em busca do “próximo reforço”
O modo como recompensas são distribuídas molda literalmente a arquitetura neural do comportamento.
Reforços previsíveis ensinam com rapidez, mas recompensas imprevisíveis mantêm o cérebro em estado de busca, sustentando a motivação e a atenção de forma contínua.
Quando aplicamos esse conhecimento conscientemente — alternando entre reforço contínuo e intermitente —, podemos condicionar o próprio cérebro para aprender mais, procrastinar menos e transformar disciplina em prazer.
Entender as programações de reforço é compreender a linguagem que o cérebro usa para decidir o que vale a pena repetir. E quem domina essa linguagem, domina também o próprio comportamento.


Sobre o autor:
Diego Jacferr é graduando em Psicologia pela Universidade Anhanguera - SP - Brasil.
Escreve artigos de divulgação científica com foco em psicologia e neurociência.